Naive Bayes Classifiers
Naive Bayes are a simple yet effective classification algorithm.
The algorithm assigns probabilities to vectors by applying conditional probabilities.
In this section, the application of naive bayes on text and record data will be demonstrated.
Record Data in R
raw data
code
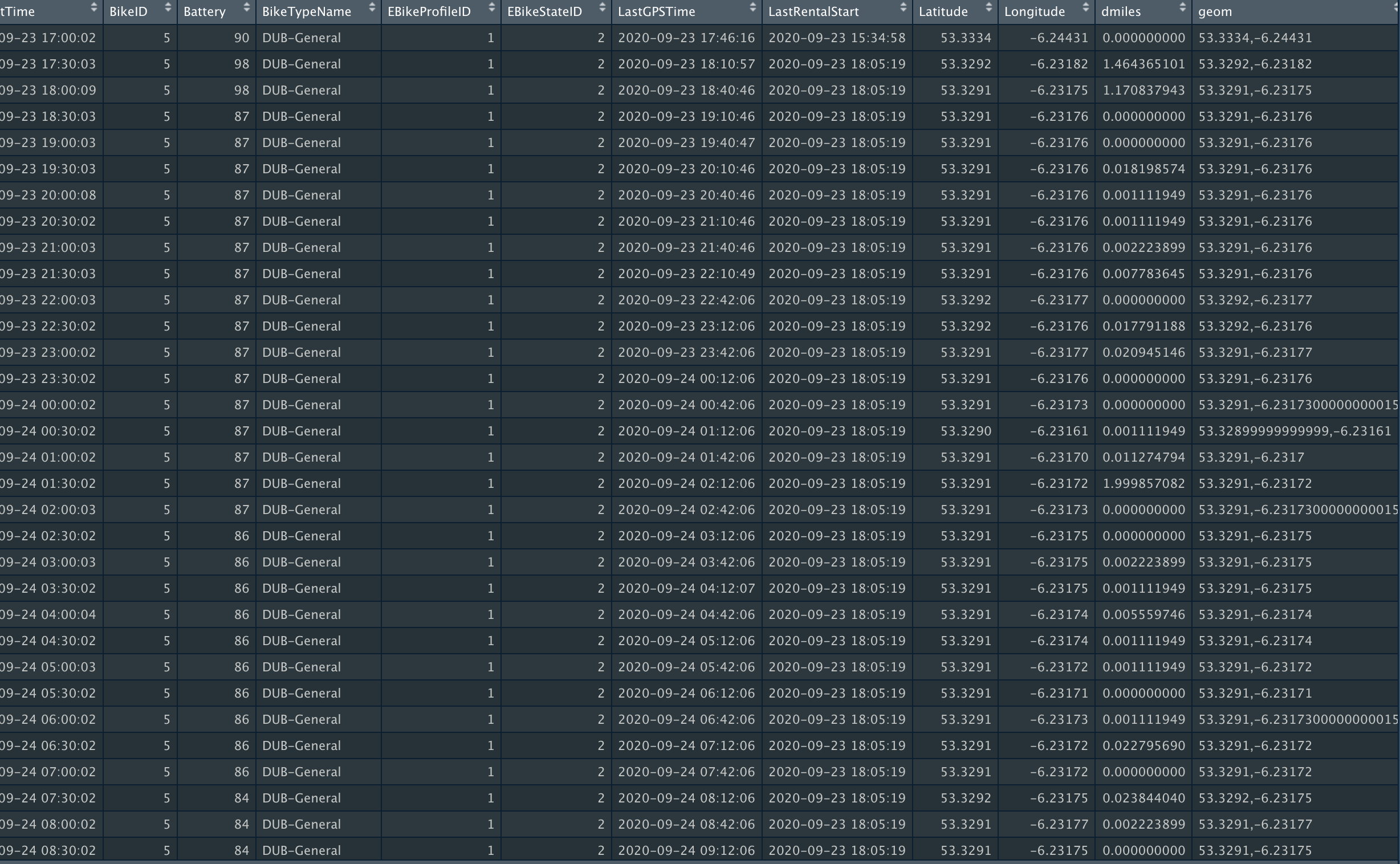
Data Cleaning:
For the Record data demonstration, the smartbikes data set will be used. The aim of this section is see if we can
predict the battery percentage of a bike, by providing other information.However, predicting the exact battery
percentage would be impossible since it is not an accurate lable. In order to over come this obstacle, the
Battery varibale was split into two groups, less than %50 and more than %50 (Discretization).
The new attribute titled "Battery.label" will be the label for our model.
Additionally, the variables BikeTypeName, EBikeStateID, weekday_int have been changed to type factor (categorical).
Data Visualizations:
After the data cleaning process, a number of visualizations were created in order
better understand the datas statistical properties.
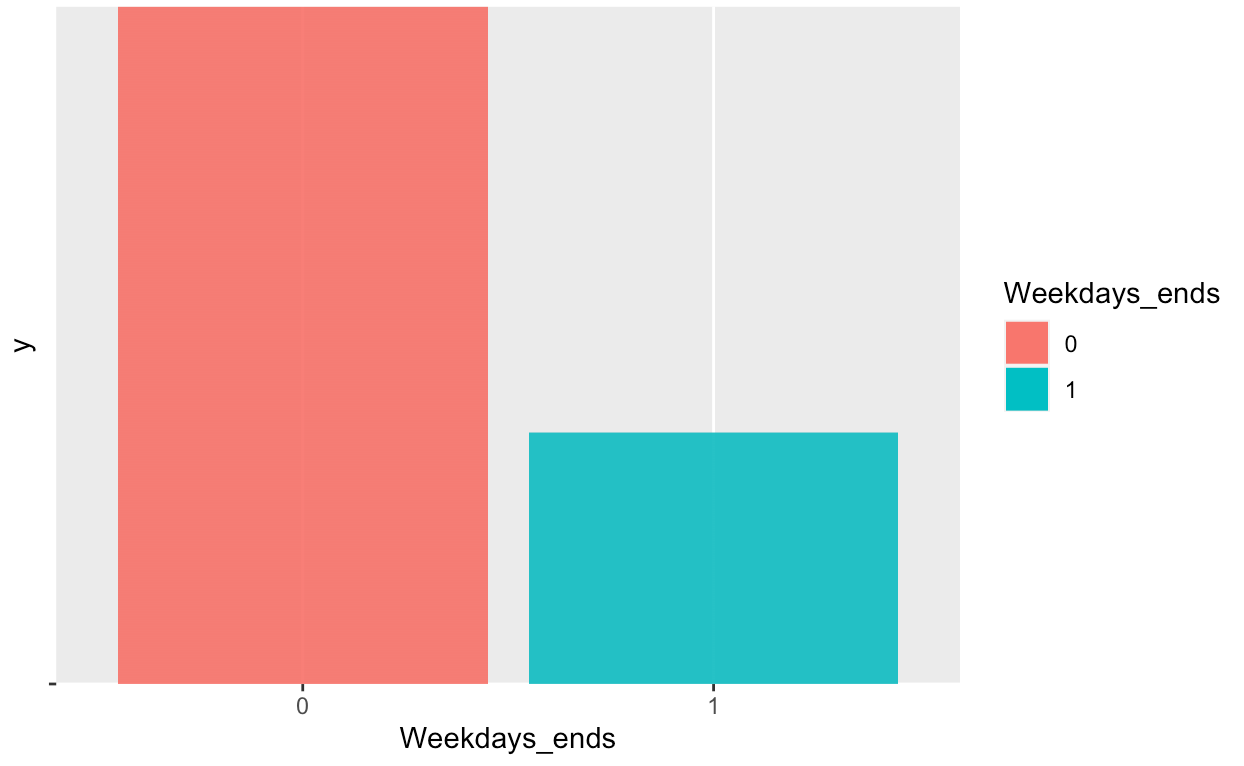
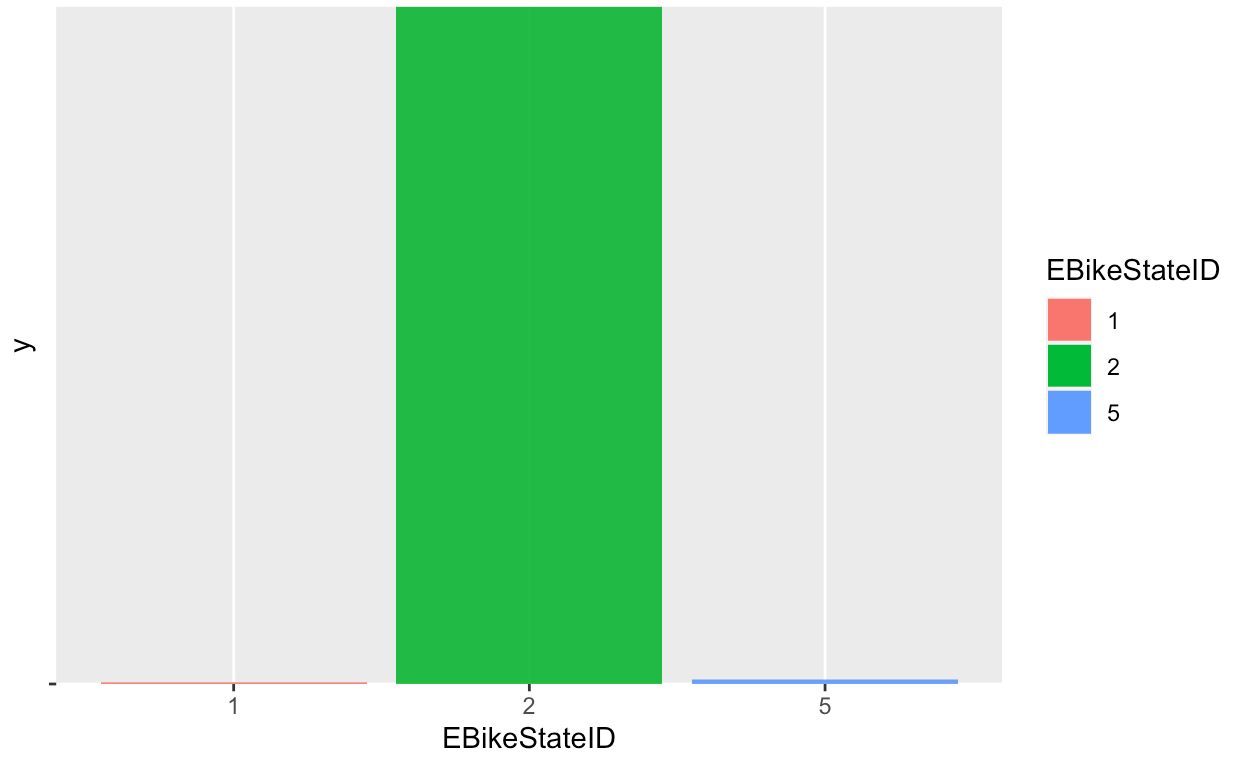
These visualizations give important information about the data. From looking at these graphs,
it can be concluded that our label "Battery. Binned" is not balanced. As such, an oversampling
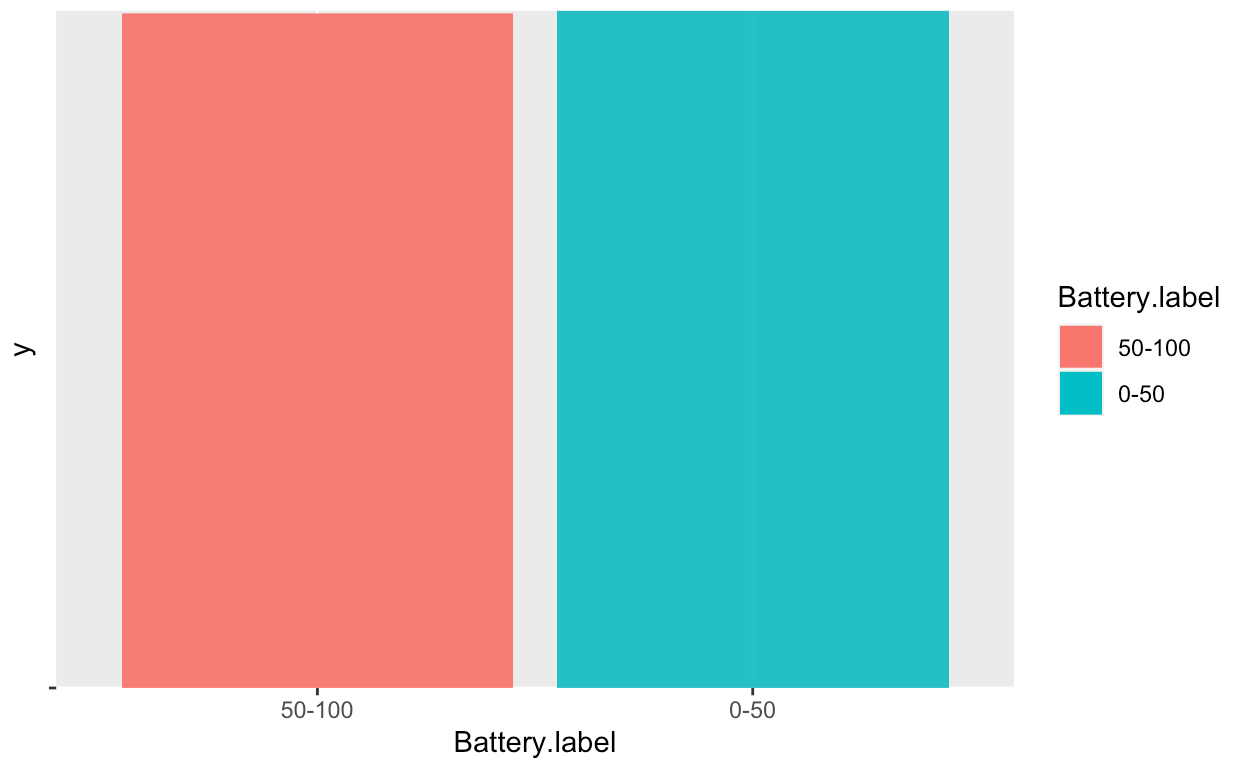
method has been applied on the less frequent "Battery.binned" value. The resutling graphs shows that
The oversampling has now balanced the dataset.
after the data cleaning process, the data set has been divided into a training set and test set. The test set is 3/4 of the entire data set. Further more, we have stored the labels for both
test set and train set in seperate data frames.
Model Building
The result of the model building is as follows.
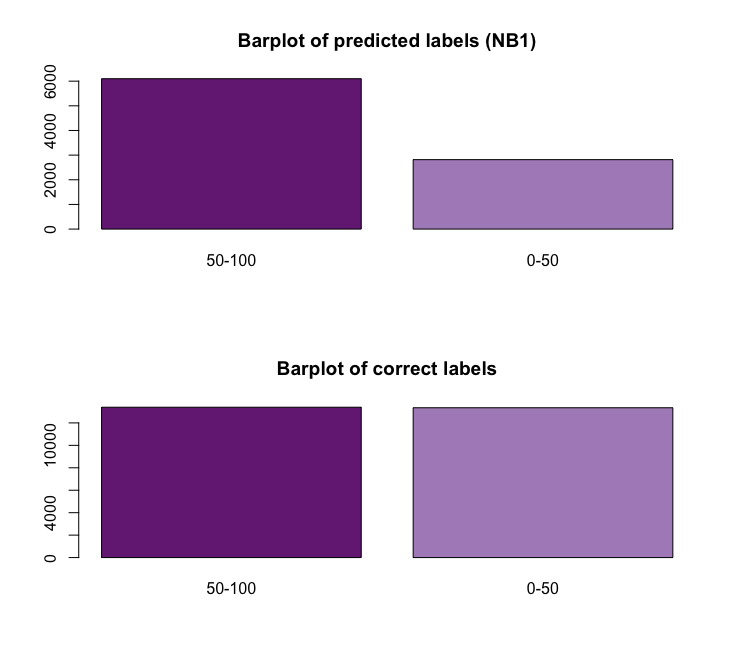
From the bar plots above it can be understood that the model tends to under predict the 0-50 class. Seeing that this is the category that was oversampled, it can be assummed that there is an over fitting issue.
Confusion Matrix Graph
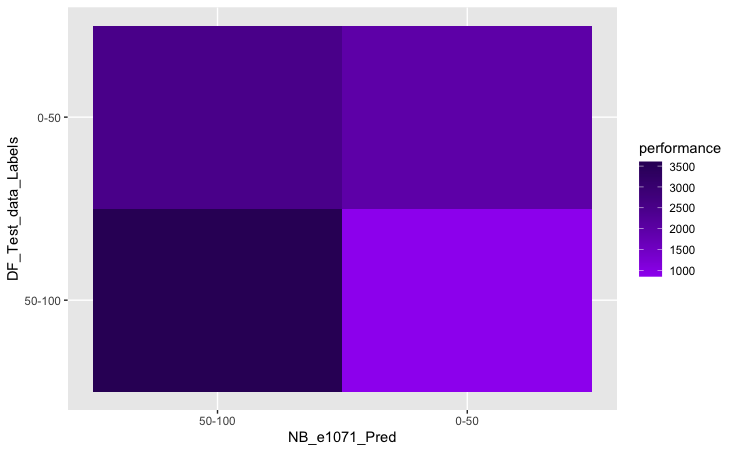
Confsuion Matrix
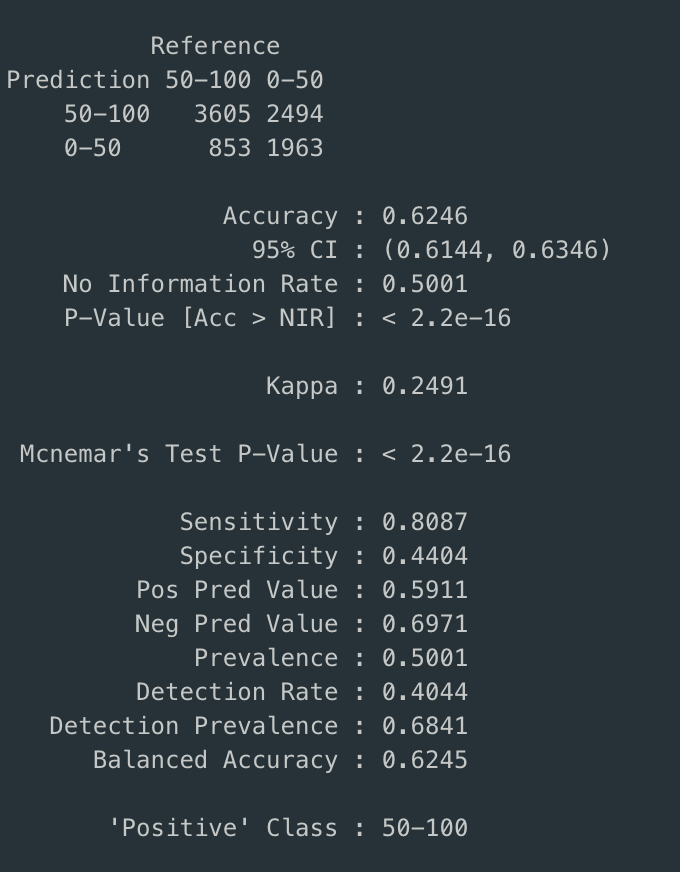
The model seems to have 62% accuracy but low specificity. This goes back to the fewer predicitons made on one of the categories.
Variable Importance plot
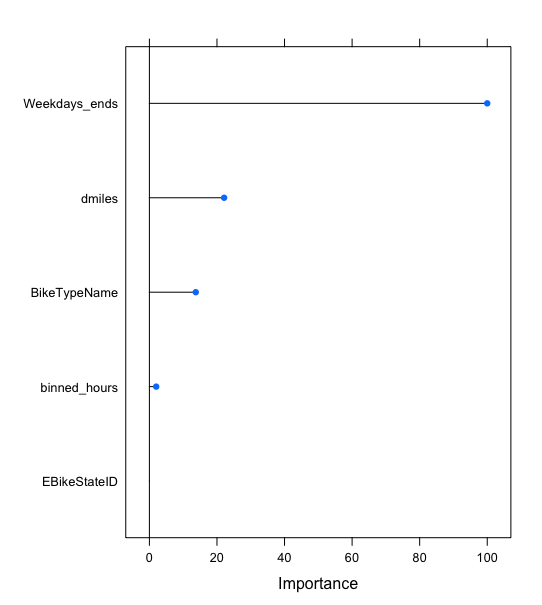
The most important variable seems to be whether it is a week day or a week end followed by the previous amount of miles traveled.
Conclusion
From the original box plots it can be concluded that the model does a better job of a particular category. With this being said, the navie bayes model predicts the label for
a given observation correctly 62% of the time. Further more it can be learned that the most important factor providing predictive ability is whether the observation was taken
on a week day or a weekend.
Text Data in Python
The smart homes commands data set will be further used for this section. In the previous section, the tokenized data set was extracted as a csv file. In this section, instead of tokenizing the original data set from the beginning, we will read in the tokenized csv file and use that for the analysis.
For simplicity, only the labels "lights","camera", "direction", "information", "weather" and "heating" were kept.
raw data
code
After splitting the data into a training and testing split, their respective labels were removed and transformed into individual data frames for further use.
Model Results
From the classification report we find that the model has a 77% accuracy rate. However, this is not across the board; the model is able to predict some labels bettern than others.
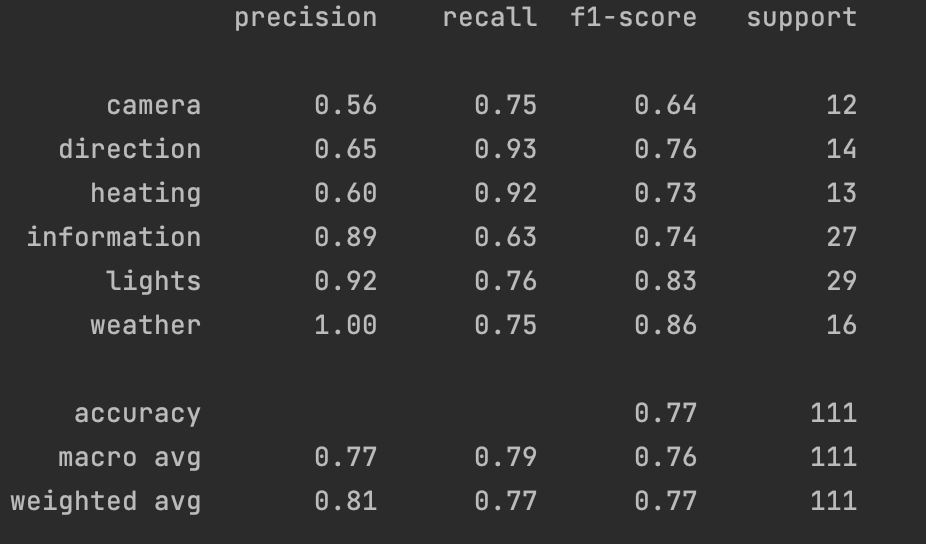
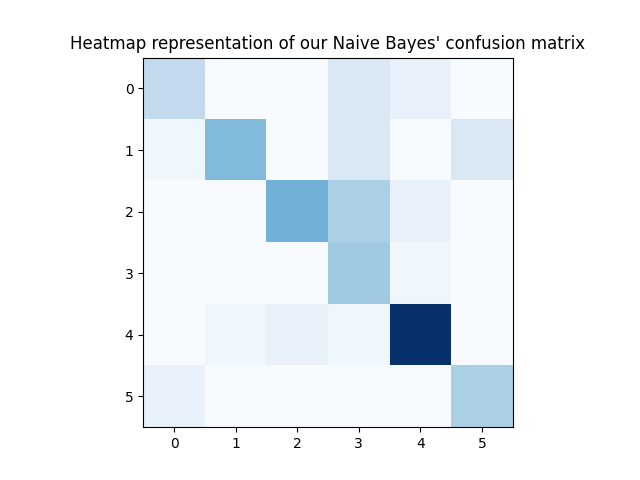
Brought below are three graphs; The first is a heat map of the condusion matrix for each label, the other two are bar garphs of the frequency of predicted lables versus the actual frequency.
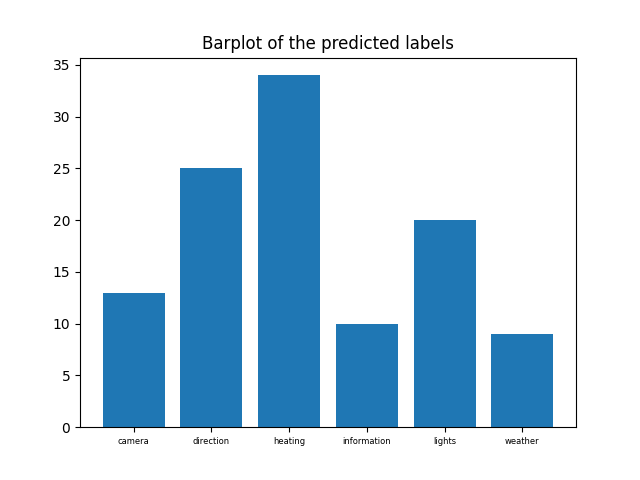
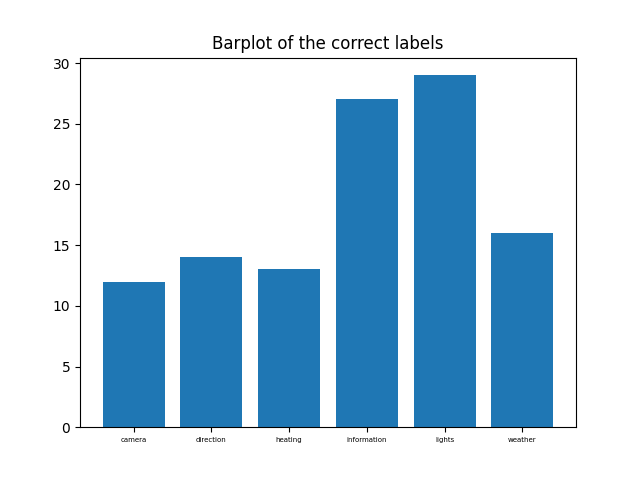
The frequency of prediction is not as accurate as one would hope for.
Conclusion
For the text data, the accuracy of the model is 77% which is quite low.
However, by looking at the confusion matrix heatmap, ones attention
is drawn to the 5th category of labels
which seems to be highly predictive.
By referring back to the confusion matrix, it can be learned that commands
given in regards to the "lights" category were predicted correctly 92% of the time.
NETID : MZ569
